项目背景
每个业务系统都有日志,当系统出现问题时,需要通过日志信息来定位和解决问题。当系统机器比较少时,登录到服务器上查看即可满足,当系统机器规模巨大,登录到机器上查看几乎不现实(分布式的系统,一个系统部署在多台机器上)
解决方案
把机器上的日志实时收集,统一存储到中心系统。再对这些日志建立索引,通过搜索即可快速找到对应的日志记录。通过提供一个界面友好的web页面实现日志展示与检索
面临的问题
实时日志量非常大,每天处理几十亿条。日志实时收集,延迟控制在分钟级别。系统的架构设计能够支持水平扩展。
业界方案
ELK

ELK方案的问题
- 运维成本高,没增加一个日志收集项,都需要手动修改配置
- 监控缺失,无法准确获取logstash的状态
- 无法做到定制化开发与维护
日志收集系统架构设计
架构设计

组件介绍
LogAgent:日志收集客户端,用来收集服务器上的日志。Lfaka: 高吞吐量的分布式队列(Linkin开发, apache顶级开源项目)ElasticSearch: 开源的搜索引擎,提供基于HTTP RESTful的web接口。Kibaa: 开源的ES数据分析和可视化工具。Hadoop:分布式计算框架,能够对大量数据进行分布式处理的平台。Storm: 一个免费的分布式实时计算系统.
将学到的技能
- 服务端agent开发
- 后端服务组件开发
- ES和Kibana的使用
- etch的使用
消息队列的通信模型
点对点模式(queue)
消费生产者生产消息发送到queue中, 然后消息消费者从queue中取出并且消费消息。一条消息被消费以后,queue中就没有了,不存在重复消费.
发布/订阅(topic)
消费生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到topic的消息会被所有订阅者消费(类似于关注了微信公众号的人都能收到推送的文章)。
补充:发布订阅模式下,当发布消息量很大时,虽然单个订阅的处理能力是不足的。实际上现实场景中是多个订阅者节点组成一个订阅组负载均衡消费topic消息即分组订阅,这样订阅者很容易实现消费能力线性扩展。可以看成是一个topic下有多个Queue,,,每个queue是点对点的方式,Queue之间是发布订阅方式。
Kafka
Apache Kafka由著名职业社交公司Linkedln开发,最初是被设计用来解决Linkedln公司内部海量日志传输等问题。Kafka使用Scala语言编写,于2011年开源进入Apache孵化器,2012年10月正式毕业,现在为Apache顶级项目
介绍
Kafka是一个分布式数据流平台,可以运行在单台服务器上,也可以在多台服务器上部署形成集群。它提供了发布和订阅功能,使用者可以发送数据到kafka中,也可以从kafka中读取数据(以便进行后续的处理)。Kafka具有高吞吐、低延迟、高容错等特点
Kafka集群架构图

- Producer: producer即生产者 ,消息的生产者,是消息的入口
- Kafka cluster: kafka集群,一台或多台服务器组成 * Broker: Broker是指部署了kafka实例的服务器节点。每个服务器上有一个或多个kafka的实例,我们姑且认为每个broker对应一台服务器。每个kafka集群内的broker都有一个不重复的编号,如图中的broker-0、broker-1等… * Topic: 消息的主题,可以理解为消息的分类,kafka的数据就保存在topic。在每个broker上都可以创建多个topic。实际应用中通常是一个业务线建一个topic。 * Partition: Topic的分区,每个topic可以有多个分区,分区的作用是做负载,提高kafka的吞吐量。同一个topic在不同的分区的数据是不重复的, partition的表现形式就是一个一个的文件夹! * Replication: 每一个分区都有多个副本,副本的作用是做备胎。当处分去(Leader)故障的时候会选择一个备胎(Follower)上位,成为leader。在kafka中默认副本的最大数量是10个,且副本的数量不能大于Broker的数量,follower和leader绝对是不不同的机器,同一机器对同一个分区也只可能存放一个副本(包括自己)。
- Consumer: 消费者,即消息的消费方,是消息的出口。
- Consumer Group: 我们可以将多个消费组成一个消费者组,在kafka的设计中同一个分区的数据只能被消费者组中某一个消费者消费。同一个消费者组的消费者可以消费同一个topic的不同分区的数据,这也是为了提高kafka的吞吐量!
流程图
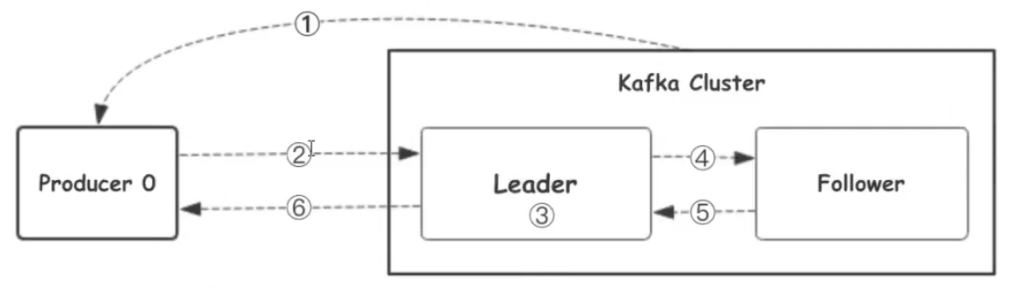
-
生产者从Kafka集群获取分区leader信息
-
生产者将消息发送给leader
-
leader将消息写入本地磁盘
-
follower从leader拉去消息数据
-
follower将消息写入本地磁盘后向leader发送ACK
-
leader收到所有的follower的ACK之后向生产者发送ACK
选择partition的原则
在kafka中,如果某个topic有多个partition, producer又怎么知道该将数据发往哪个partition呢?
- partition在写入的时候可以指定需要写入的partition, 如果有指定,则写入对应的partition。
- 如果没有指定的partition, 但是设置了数据的key,则会根据key的值hash处一个partition。
- 如果既没有指定partition, 又没有设置key,则会采用轮训方式,即每次取一小段时间的数据写入某个partition, 下一小段的时间写入下一个partition.
ACK应答机制
producer在向kafka写入消息的时候,可以设置参数来确定是否确认kafka接收数据,这个参数可设置的值为0、1、all.
-
0代表producer往集群发送数据不需要等到集群的返回,不确保消息发送成功。安全性最低但是效率最高。
-
1代表producer往集群发送数据只要leader应答就可以发送下一条,只确保leader发送成功
-
all代表producer往集群发送数据需要所有的follower都完成从leader的同步才会发送下一条,确保leader发送成功和所有的副本都完成备份。安全性最高,但是效率最低
最后要注意的是,如果往不存在的topc写数据,kafka会自动创建topic,partition和replicatin的数量默认配置都是1.
Topic和数据日志
topic是同一类别的消息记录(record)的集合。在kafka中,一个主题通常有多个订阅者。对于每个主题,kfaka集群维护了一个分区数据日志文件结构如下:
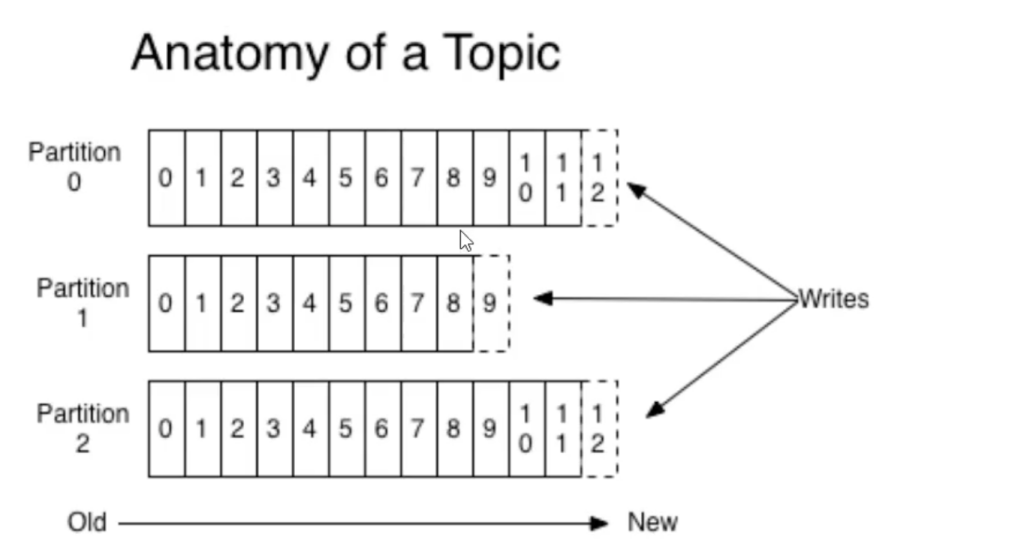
每个partition都是一个有序并且不可变得消息记录集合。当新的数据写入时,就被追加到partition的末尾。在每个partition中, 每条消息都会被分配一个顺序的唯一标识,这个标识被称为offset, 即偏移量。注意,kafka只保证在同一个partition内部消息是有序的,在不同partition之间,并不能保证消息有序。
kafka可以配置一个保留期限,用来标识日志会在kafka集群内保留多长时间。kafka集群会保留在保留期限内的所有被发布的消息,不管这些消息是否被消费过。比如保留期限设置为两天,那么数据被发布到kafka集群的两天内,所有的这些数据都可以被消费。当超过两天,这些数据将会被清空,以便为后续的数据腾出空间。由于kafka会将数据进行持久化村粗(即写入磁盘上),所有保留的数据大小可以设置为一个比较大的值。
Partition结构
Partition在服务器上的表现形式就是一个一个的文件夹。每个Partition的文件夹下面会有多组segment文件,每组segment文件包含.index文件、.log文件、.timeindex文件三个文件,其中.log文件就是实际村粗的message的地方,而.index和.timeindex文件为索引文件,用于检索消息。
消费数据
多个消费者实例可以组成一个消费者组,并用一个标签来标识这个消费者组。一个消费者组中的不同消费者实例可以运行在不同的进程甚至不同的服务器上。
如果所有的消费者实例都在同一个消费者组中,那么消费记录会被很好的均衡的发送到每个消费者实例。
如果所有的消费者实例都在不同的消费者组,那么每一条消息记录会被广播到每一个消费者实例。