代码地址: github
Elasticsearch 是基于 Apache Lucene 的开源分布式搜索和分析引擎。与主要目的是存储数据的典型 SQL 和 NoSQL 数据库不同,Elasticsearch 可以存储和索引数据,以便可以快速搜索和分析数据。它还与 Logstash(一种数据处理管道,可以从日志和数据库等多个来源获取数据)和 Kibana(用于数据可视化)集成,它们共同构成了 ELK 堆栈。
在本教程中,我们将探索如何结合 Elasticsearch 和 Golang 的强大功能。我们将构建一个基本的内容管理系统,该系统能够创建、读取、更新和删除帖子,以及通过 Elasticsearch 搜索帖子的能力。
环境要求
- Go(version >= 1.23.8) installed on your machine
- 已安装Docker 和 Docker-compose
- 熟悉 Docker 和 Go 编程语言
开始
- lib/pq — 与 Go 标准库中的 database/sql 包兼容的 Go 的 PostgreSQL 驱动程序
- elastic/go-elasticsearch — Golang 的官方 Elasticsearch 客户端
- gin-gonic/gin — 我们将用于应用程序的 REST API 的 HTTP 框架
- rs/zerolog — 轻量级记录器
通过在终端中运行以下命令来安装依赖项:
go get github.com/lib/pq github.com/elastic/go-elasticsearch github.com/gin-gonic/gin github.com/rs/zerolog
接下来,在项目目录中创建所需的文件夹和文件以匹配以下结构:
├── cmd
│ ├── api
│ │ └── main.go
├── db
│ ├── database.go
│ └── posts.go
├── .env
├── handler
├── logstash
│ ├── config
│ ├── pipelines
│ └── queries
└── models
└── post.go
cmd — 这是应用程序二进制文件(即 `main. go 文件)
db — db 包充当应用程序和数据库之间的桥梁。我们稍后还将使用它来存储数据库迁移文件
.env — 包含环境变量的 “key-value” 映射(例如,数据库凭证)
handler — handler 包包括由 gin 框架提供支持的 API 路由处理程序 logstash— 这是我们保存与 logstash 相关的代码的地方,例如管道配置和随附的Dockerfile
models — 模型是可以编组到适当的 JSON 对象中的 Golang 结构
打开 . env文件,并设置环境变量,如下所示:
POSTGRES_USER=letterpress
POSTGRES_PASSWORD=letterpress_secrets
POSTGRES_HOST=postgres
POSTGRES_PORT=5432
POSTGRES_DB=letterpress_db
ELASTICSEARCH_URL=http://elasticsearch:9200
打开posts.go文件(在 models 文件夹中)并设置 Post 结构体:
package models
type Post struct {
ID int `json:"id,omitempty"`
Title string `json:"title"`
Body string `json:"body"`
}
接下来,将以下代码添加到 db/database。 去要管理数据库连接:
package db
import (
"database/sql"
_ "github.com/lib/pq"
"github.com/rs/zerolog"
)
type Database struct {
Conn *sql.DB
Logger zerolog.Logger
}
func Init(logger zerolog.Logger) (Database, error) {
db := Database{}
dsn := "postgres://letterpress:letterpress_secrets@postgres:5432/letterpress_db?sslmode=disable"
conn, err := sql.Open("postgres", dsn)
if err != nil {
return db, err
}
db.Conn = conn
db.Logger = logger
err = db.Conn.Ping()
if err != nil {
return db, err
}
return db, nil
}
在上面的代码中,我们设置了数据库配置并添加了一个 Logger 字段,然后该字段可用于记录数据库错误和事件
另外,打开 db/posts.go并实现我们很快将创建的 POSTS 和 post_logs 表的数据库作:
package db
import (
"database/sql"
"fmt"
"letterpress/models"
)
var (
ErrNotRecord = fmt.Errorf("no matching record found")
insertOp = "insert"
deleteOp = "delete"
updateOp = "update"
)
func (db Database) SavePost(post *models.Post) error {
var id int
query := `INSERT INTO posts(title, body) VALUES ($1, $2) RETURNING id`
err := db.Conn.QueryRow(query, post.Title, post.Body).Scan(&id)
if err != nil {
return err
}
logQuery := `INSERT INTO post_logs(post_id, operation) VALUES ($1, $2)`
post.ID = id
_, err = db.Conn.Exec(logQuery, post.ID, insertOp)
if err != nil {
db.Logger.Err(err).Msg("could not log operation for logstash")
}
return nil
}
在上面,我们实现了一个 SavePost 函数,该函数在数据库中插入 Post 参数。如果插入成功,它会继续将作和为新帖子生成的 ID 记录到 post_logs 表中。这些日志发生在应用程序级别,但如果您觉得您的数据库作并不总是通过应用程序,您可以尝试使用触发器在数据库级别执行此作。Logstash 稍后将使用这些日志将我们的 Elasticsearch 索引与我们的应用程序数据库同步。
使用 golang-migrate 进行数据库迁移
虽然 PostgreSQL 会在 Docker 容器中设置应用程序数据库时自动创建应用程序数据库,但我们需要自己设置表。为此,我们将使用 golang-migrate/migrate 来管理我们的数据库迁移 。使用本指南安装 migrate 并运行以下命令,为 posts 表生成迁移文件:
$ migrate create -ext sql -dir db/migrations -seq create_posts_table
$ migrate create -ext sql -dir db/migrations -seq create_post_logs_table
Elasticsearch 和 PostgreSQL 作为 Docker 容器
version: "3"
services:
postgres:
image: postgres
restart: unless-stopped
hostname: postgres
env_file: .env
ports:
- "5432:5432"
volumes:
- pgdata:/var/lib/postgresql/data
api:
build:
context: .
dockerfile: Dockerfile
hostname: api
env_file: .env
ports:
- "8080:8080"
depends_on:
- postgres
elasticsearch:
image: "docker.elastic.co/elasticsearch/elasticsearch:7.10.2"
environment:
- discovery.type=single-node
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ports:
- "9200:9200"
volumes:
- esdata:/usr/share/elasticsearch/data
volumes:
pgdata:
driver: local
esdata:
driver: local
postgres — 我们的应用程序将使用的 PostgreSQL 数据库。它还公开了默认的 PostgreSQL 端口,以便我们可以从容器外部访问我们的数据库
api — 这是我们应用程序的 REST API,它允许我们创建和搜索帖子
elasticsearch — 为我们的搜索功能提供支持的 Elasticsearch 映像。我们还将发现类型设置为 single-node,因为我们处于开发环境中
接下来,在项目文件夹中创建项目的 Dockerfile,并使用以下代码填充它:
FROM golang:1.23.8
RUN mkdir -p /letterpress
COPY go.mod go.sum /letterpress/
WORKDIR /letterpress
RUN go mod download
RUN go mod tidy
COPY . /letterpress
RUN go build -o /usr/bin/letterpress /letterpress/cmd/api
EXPOSE 8080 8080
ENTRYPOINT [ "/usr/bin/letterpress" ]
在上面的代码中,我们设置了 Docker,以使用适用于 Go 的 Debian buster 镜像来构建我们的应用程序。接下来,它下载应用程序依赖项,构建应用程序,并将生成的二进制文件复制到 /usr/bin。
虽然我们还没有实现 REST API,但您可以通过在终端中运行 docker-compose up--build 来启动服务来试用到目前为止的进展。
在 PostgreSQL 服务运行时,将数据源名称 (DSN) 导出为环境变量,并通过从项目根目录运行以下命令来应用我们创建的迁移:
migrate -database 'postgres://letterpress:letterpress_secrets@localhost:5432/letterpress_db?sslmode=disable' -path db/migrations/ up
使用 gin-gonic/gin 的路由处理程序
要设置我们的 API 路由,请创建一个新handler.go文件,并将其设置为初始化和注册相关路由:
package handler
import (
"letterpress/db"
"github.com/elastic/go-elasticsearch/v7"
"github.com/gin-gonic/gin"
"github.com/rs/zerolog"
)
type Handler struct {
DB db.Database
Logger zerolog.Logger
ESClient *elasticsearch.Client
}
func New(database db.Database, esClient *elasticsearch.Client, logger zerolog.Logger) *Handler {
return &Handler{
DB: database,
ESClient: esClient,
Logger: logger,
}
}
func (h *Handler) Register(group *gin.RouterGroup) {
group.GET("/posts/:id", h.GetPost)
group.PATCH("/posts/:id", h.UpdatePost)
group.DELETE("/posts/:id", h.DeletePost)
group.GET("/posts", h.GetPosts)
group.POST("/posts", h.CreatePost)
group.GET("/search", h.SearchPosts)
}
这些路由为我们的文章公开了一个 CRUD 接口,以及一个搜索端点,允许使用 Elasticsearch 搜索所有文章。
创建 posts.go 文件添加到同一 handlers 目录中,并添加上述路由处理程序的实现(为简洁起见,我们将介绍如何创建和搜索帖子,但您可以在项目的 Github 仓库中看到其他处理程序的完整实现):
使用 Logstash 将数据库同步到 Elasticsearch
Logstash 是一个数据处理管道,它从不同的输入源获取数据,对其进行处理,然后将其发送到输出源。
由于目标是通过 Elasticsearch 搜索数据库中的数据,因此我们将 Logstash 配置为使用 PostgreSQL 数据库作为其输入,使用 Elasticsearch 作为输出。
在 logstash/config 目录中,创建一个新pipelines.yml 文件来保存我们需要的所有 Logstash 管道。对于此项目,它是将数据库与 Elasticsearch 同步的单个管道。在新管道中添加以下代码 :
- pipeline.id: sync-posts-pipeline
path.config: "/usr/share/logstash/pipeline/sync-posts.conf"
接下来,添加 sync-posts.conf文件,其中包含以下代码来设置输入和输出源:
input {
jdbc {
jdbc*connection_string => "jdbc:postgresql://${POSTGRES_HOST}:5432/${POSTGRES_DB}"
jdbc_user => "${POSTGRES_USER}"
jdbc_password => "${POSTGRES_PASSWORD}"
jdbc_driver_library => "/opt/logstash/vendor/jdbc/postgresql-42.3.1.jar"
jdbc_driver_class => "org.postgresql.Driver"
statement_filepath => "/usr/share/logstash/config/queries/sync-posts.sql"
use_column_value => true
tracking_column => "id"
tracking_column_type => "numeric"
schedule => "*/5 \_ \* \* \* \*"
}
}
filter {
mutate { # remove unneeded fields including ones that were added by logstash
remove_field => ["@version", "@timestamp"]
}
}
output {
stdout { codec => rubydebug { metadata => true } }
if [operation] == "delete" {
elasticsearch {
hosts => ["http://elasticsearch:9200"] # URL of the ES docker container - docker would resolve it for us.
action => "delete"
index => "posts"
document_id => "%{post_id}"
}
} else if [operation] in ["insert", "update"] {
elasticsearch {
hosts => ["http://elasticsearch:9200"] # URL of the ES docker container - docker would resolve it for us.
action => "index"
index => "posts"
document_id => "%{post_id}"
}
}
}
上面的配置文件由三个块组成:
* `input` — 使用 [JDBC](https://www.elastic.co/guide/en/logstash/current/plugins-integrations-jdbc.html) 插件建立与 PostgreSQL 的连接,并指示 Logstash 每 5 秒运行一次由
* `statement_filepath` 指定的 SQL 查询(由 `schedule` 值配置)。虽然 *schedule* 具有类似 cron 的语法,但它也支持亚分钟间隔并在后台使用 [rufus-scheduler](https://github.com/jmettraux/rufus-scheduler)。您可以[在此处](https://github.com/jmettraux/rufus-scheduler#parsing-cronlines-and-time-strings)了解有关语法及其配置的更多信息。我们还会跟踪 `id` 列,以便 Logstash 仅获取自上次运行管道以来记录的作
* `filter` — 删除不需要的字段,包括 Logstash 添加的字段
* `output` — 负责将输入数据移动到我们的 Elasticsearch 索引中。它使用 ES 条件从索引中删除文档(如果数据库中的 operation 字段是 delete)或创建/更新文档(如果作是 insert 或 update)
您可以浏览有关输入 、 筛选和输出插件的 Logstash 文档,以了解每个块中的更多功能。
接下来,创建一个 sync-posts.sql 文件来容纳管道的 SQL 语句:
SELECT l.id,
l.operation,
l.post_id,
p.id,
p.title,
p.body
FROM post_logs l
LEFT JOIN posts p
ON p.id = l.post_id
WHERE l.id > :sql_last_value ORDER BY l.id;
SELECT 语句使用 SQL 联接根据 post_logs 表中的 post_id 获取相关文章。
配置 Logstash 后,我们现在可以设置其 Dockerfile 并将其添加到我们的 docker-compose 服务中。在 logstash 文件夹中创建一个名为 Dockerfile 的新文件,并将以下代码添加到该文件中:
# 使用最新的 Logstash 镜像
FROM docker.elastic.co/logstash/logstash:8.6.0
# 安装最新的 JDBC 插件
RUN /opt/logstash/bin/logstash-plugin install logstash-integration-jdbc
# 安装 PostgreSQL JDBC 驱动
RUN mkdir -p /opt/logstash/vendor/jdbc && \
curl -o /opt/logstash/vendor/jdbc/postgresql-42.3.1.jar https://jdbc.postgresql.org/download/postgresql-42.3.1.jar
# 设置 Logstash JVM 配置(根据需要调整)
ENV LOGSTASH_JAVA_OPTS="-Xmx1g -Xms512m -XX:+UseG1GC"
# 设置启动命令
ENTRYPOINT ["/usr/local/bin/docker-entrypoint"]
上面的 Dockerfile 采用官方 Logstash 镜像,并设置我们的管道所需的 JDBC 插件以及 PostgreSQL JDBC 驱动程序。
更新 docker-compose.yml 文件,方法是将 Logstash 添加到服务列表(即 volumes` 块之前),如下所示
logstash:
build:
context: logstash
env_file: .env
environment:
- LOGSTASH_JAVA_OPTS=-XX:+UseG1GC -Xms2g -Xmx4g
volumes:
- ./logstash/config/pipelines.yml:/usr/share/logstash/config/pipelines.yml
- ./logstash/pipelines/:/usr/share/logstash/pipeline/
- ./logstash/queries/:/usr/share/logstash/config/queries/
depends_on:
- postgres
- elasticsearch
Logstash 服务使用包含 Dockerfile 的 logstash 目录作为其上下文。它还使用卷将前面的配置文件挂载到 Logstash 容器中的相应目录中。
构建我们的 API 二进制文件
现在,我们已准备好将项目公开为 HTTP API。我们将通过 main 来做到这一点 main.go驻留在 CMD/API 中。在编辑器中打开它,并向其添加以下代码
package main
import (
"os"
"letterpress/db"
"letterpress/handler"
"github.com/elastic/go-elasticsearch/v7"
"github.com/gin-gonic/gin"
"github.com/rs/zerolog"
)
func main() {
var err error
logger := zerolog.New(os.Stderr).With().Timestamp().Logger()
dbInstance, err := db.Init(logger)
if err != nil {
logger.Err(err).Msg("Connection failed")
os.Exit(1)
}
logger.Info().Msg("Database connection established")
esClient, err := elasticsearch.NewDefaultClient()
if err != nil {
logger.Err(err).Msg("Connection failed")
os.Exit(1)
}
h := handler.New(dbInstance, esClient, logger)
router := gin.Default()
rg := router.Group("/v1")
h.Register(rg)
router.Run(":8080")
}
首先,我们设置一个 Logger 并将其传递给所有应用程序组件,以确保错误和事件日志是一致的。接下来,我们使用环境变量(由 . 环境文件)。我们还连接到 Elasticsearch 服务器并确保其可访问性。然后,我们初始化路由处理程序并在端口 8080 上启动 API 服务器。请注意,我们还使用 gin 的路由组将所有路由放在 v1 命名空间下,这样,我们还为我们的 API 提供了一种“版本控制”。
测试我们的搜索应用程序
此时,我们现在可以试用我们的搜索应用程序。通过在终端中运行 docker-compose up --build 来重新构建并启动 docker-compose 服务。该命令还应在 http://localhost:8089 上启动 API 服务器。
打开您最喜欢的 API 测试工具(例如 Postman、cURL、HTTPie 等)并创建一些帖子
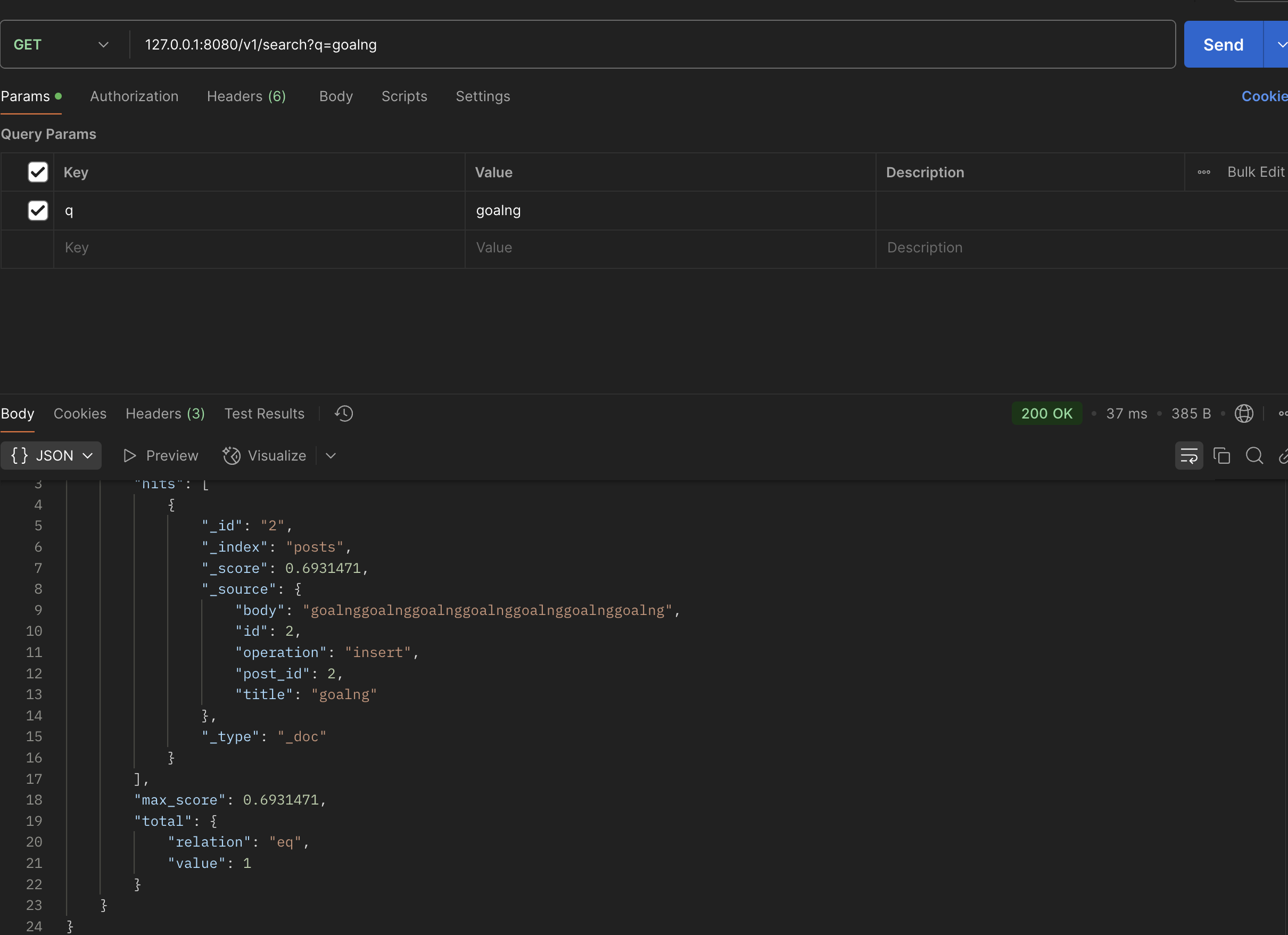
要测试搜索终端节点,请向 http://localhost:8089/v1/search 发出 HTTP GET 请求,如下面的 Postman 屏幕截图所示:
使用 Kibana 实现 Elasticsearch 可视化
虽然我们始终可以使用 Elasticsearch API 来查看 Elasticsearch 服务器中发生的情况或查看索引中当前的文档,但有时在定制的仪表板中可视化和探索这些信息会很有帮助。Kibana 使我们能够做到这一点。通过在 services 部分(即,在 logstash 服务之后但在 volumes 部分之前)添加以下代码,更新 docker-compose 文件以包含 Kibana 服务:
kibana:
image: "docker.elastic.co/kibana/kibana:7.10.2"
ports:
- "5601:5601"
hostname: kibana
depends_on:
- elasticsearch
我们使 Kibana 依赖于 Elasticsearch 服务,因为如果 Elasticsearch 没有启动和运行,它将毫无用处。我们还公开了默认的 Kibana 端口,以便我们可以从开发计算机访问控制面板。
通过运行 docker-compose up 启动 docker-compose 服务(如果它们正在运行,则必须先在 docker-compose down 的情况下停止它们)。访问 http://localhost:5601 以访问 Kibana 控制面板。
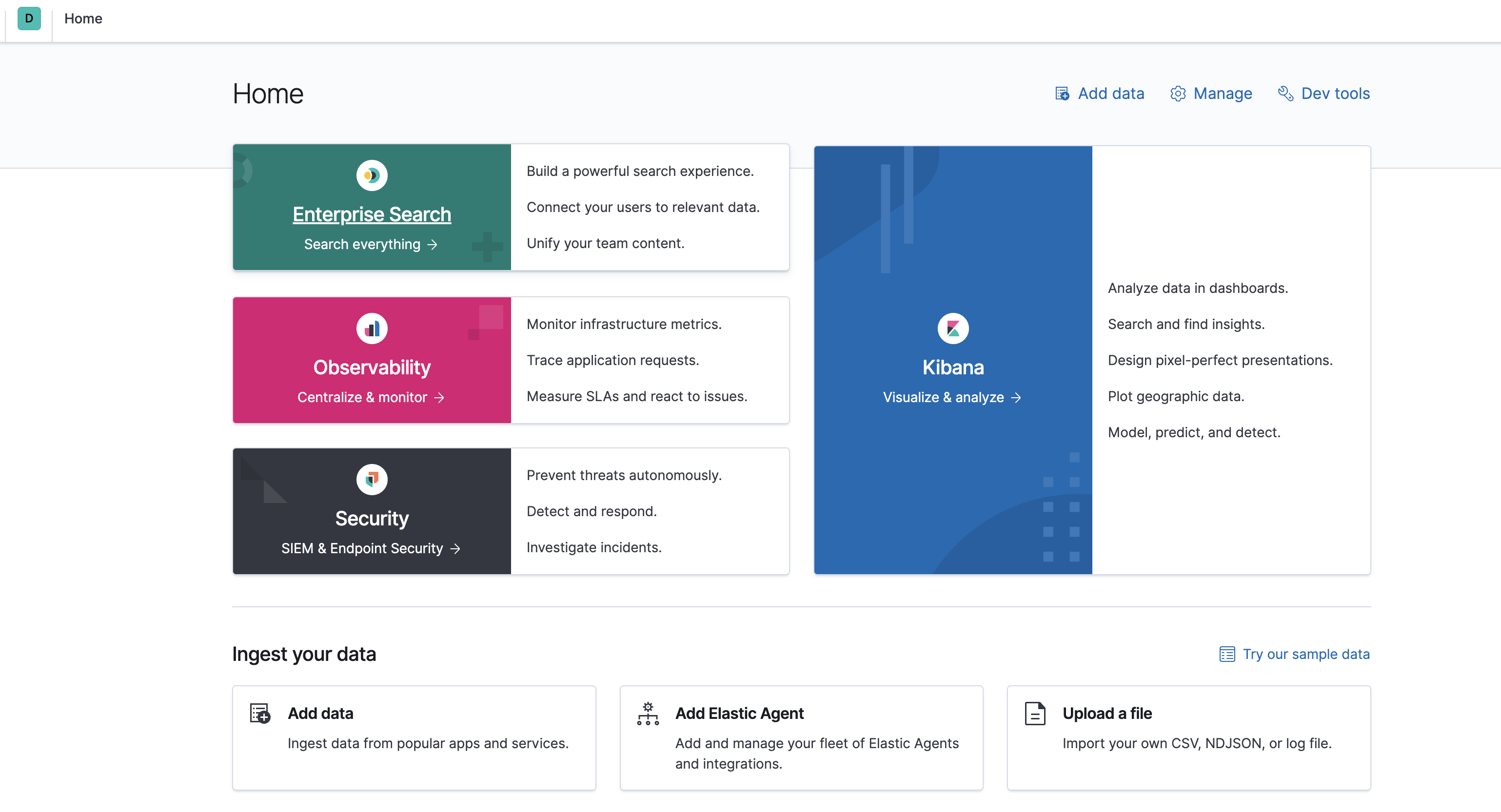
您还可以使用 Dev Tools 查看 posts 索引中的所有文档,或者在应用程序中使用它们之前尝试不同的搜索查询。在下面的屏幕截图中,我们使用 match_all 列出所有索引的帖子: